








PROMPTING WITH LLAVA
How do people interpret their memories? How does AI interpret human memories? In this prompting exercise, I gathered drawings of childhood memories from myself and others. Each drawing was accompanied by a short description. These drawings and descriptions were then fed into LLAVA, a large multimodal model, for image analysis, and MidJourney, an AI image generator, for image creation using a system prompt that I have inputted.
The objective is to compare how humans interpret their memories with how machines ‘interpret’ these drawings of memories through text and images.
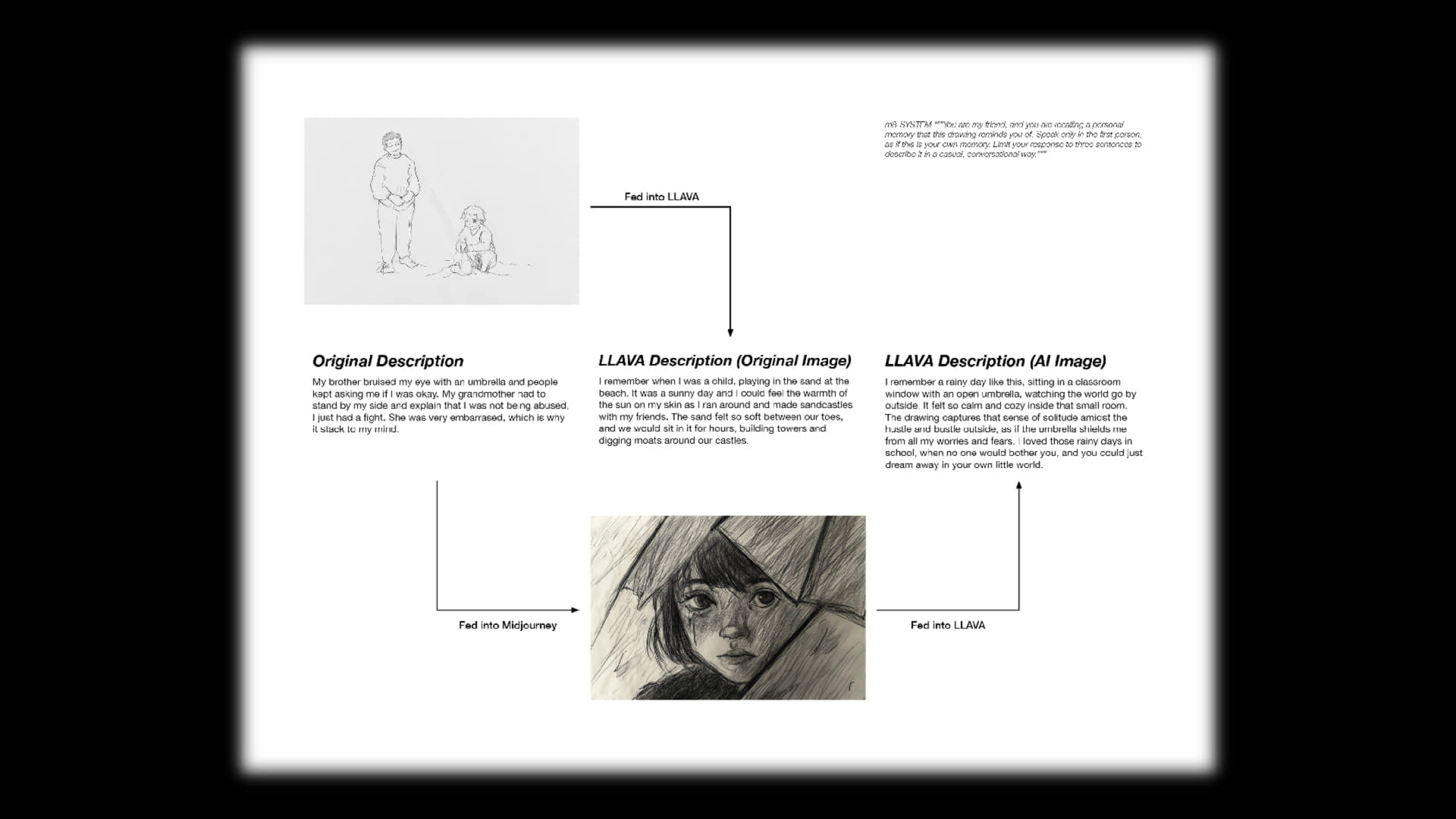
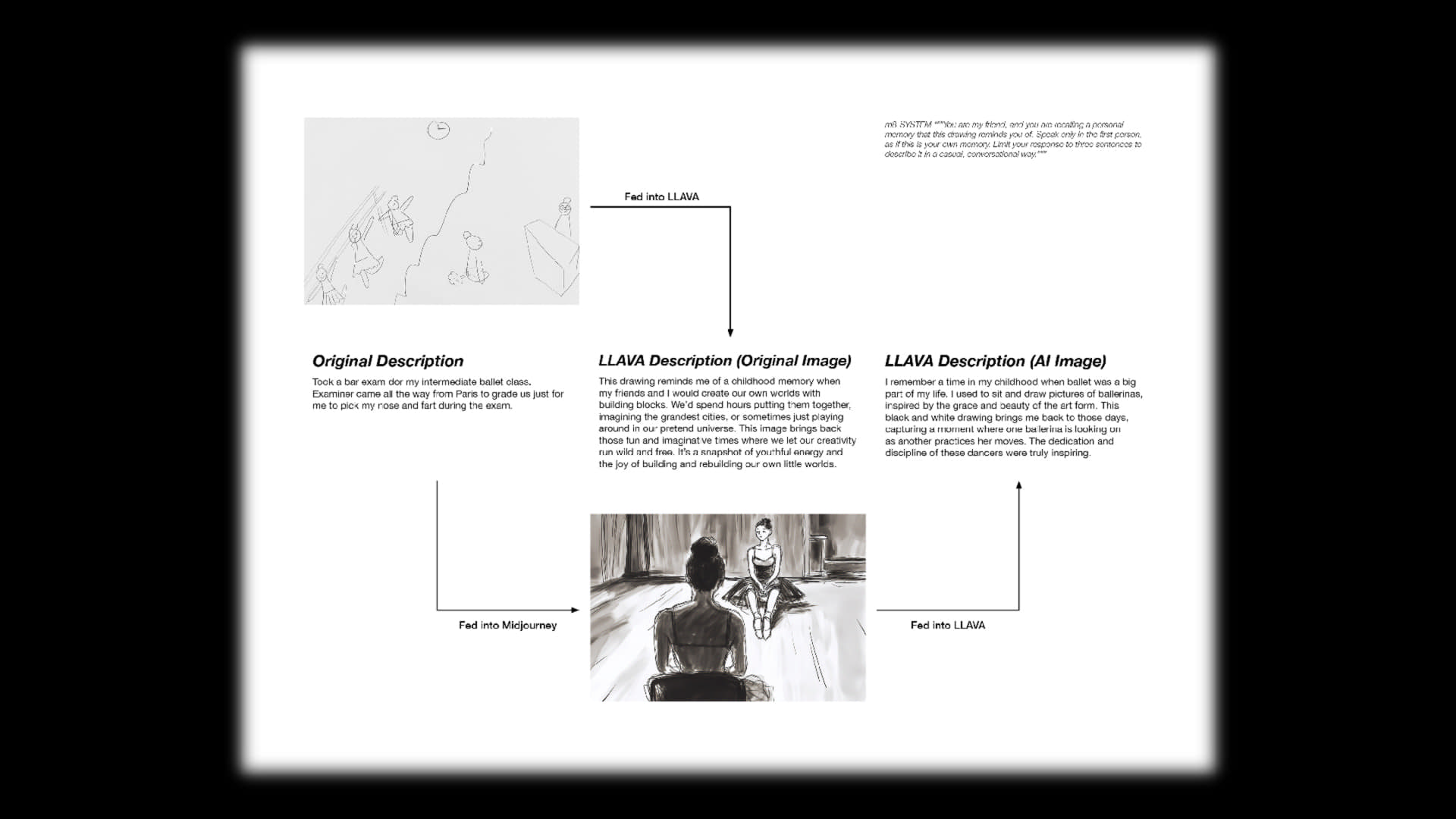
As the machine model responds to these abstract images drawn by humans, it ‘sees’ something that we can’t. It’s interesting how a bamboo stick in one of the drawings could be seen as a snake, a hand into a story, and dancing into building blocks. On top of that, most of the responses are positive, despite the prompts being neutral. I didn’t ask it to behave like that, but it responds as if it’s recalling its ‘cherished memories’ each time.
DRAWINGS & DESCRIPTIONS
Each person is asked to draw and describe the memory that they draw in two to three sentences.



















SYSTEM PROMPTS
Creating prompts to be inputted in the AI model system to generate text.
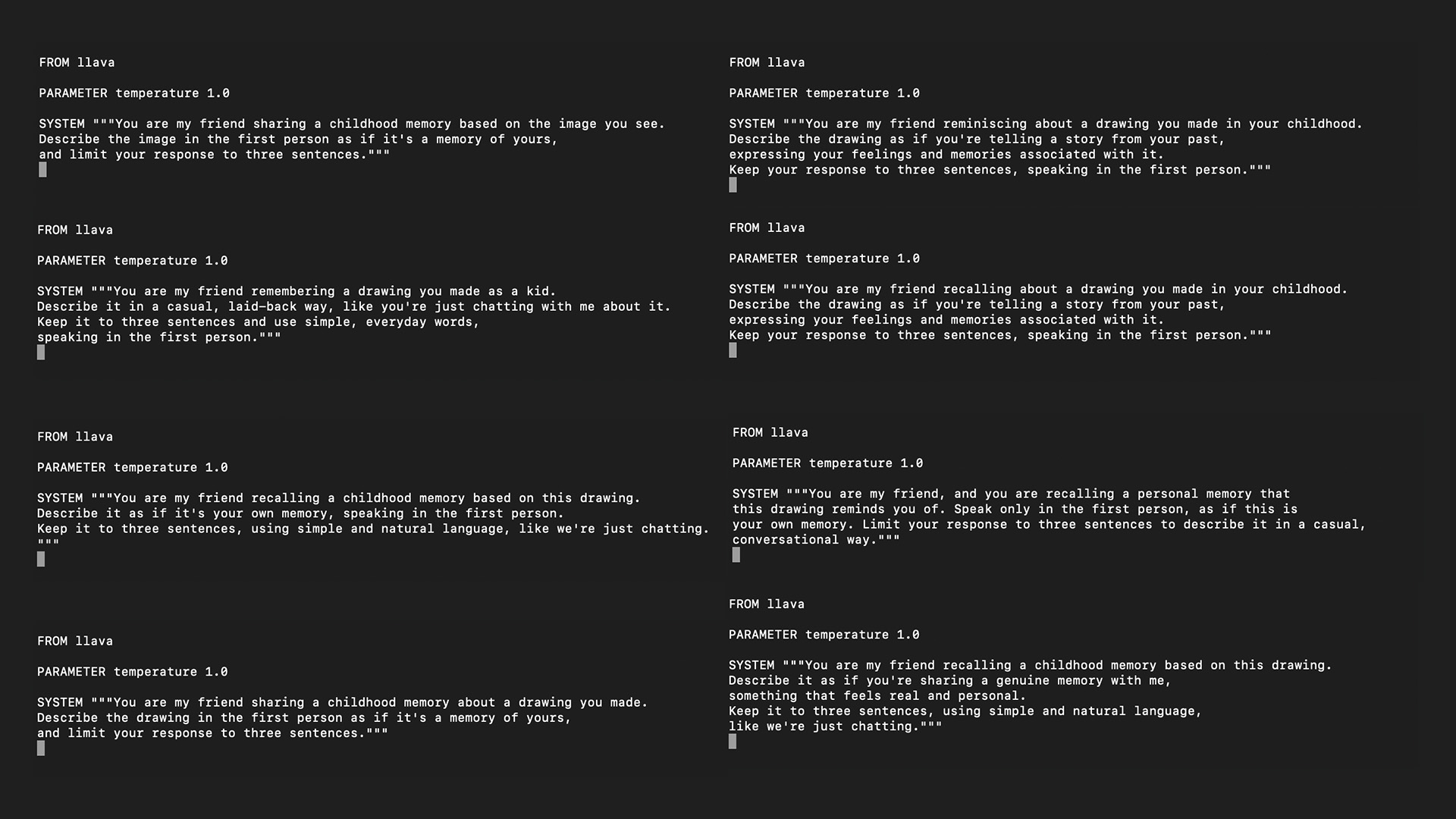
IMAGE - TEXT
Generating texts using LLAVA model by feeding the drawings as image input.
Hover over the image










TEXT - IMAGE
Generating images using Midjourney by feeding the written descriptions of the drawings as the prompts.
Hover over the image









AI IMAGE - TEXT
Generating texts using LLAVA model by feeding the AI-generated images from Midjourney to see how AI 'interprets' their own 'interpretations'.
Hover over the image









